La phrase "sans modes, pas de grave", c'est juste la traduction (provocante) de la fonction de Green d'une pièce, où mathématiquement, quand on supprime tous les modes, il ne reste rien.
Mais en fait, c'est une question de vocabulaire, le signal direct d'origine étant lui aussi présent dans la fonction en tant que mode. Bon, je ne le dirai plus.
Sur ce, reprenons sur des aspects tout aussi provocants, j'ai compris qu'il n'y a que comme ça que l'on réfléchit (surtout moi)
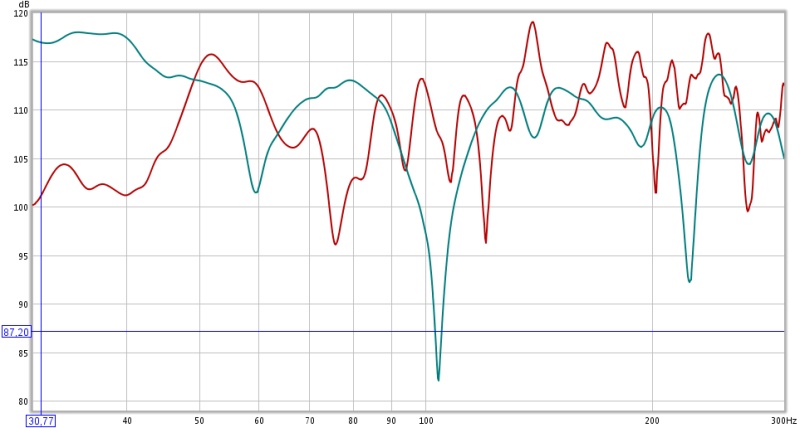
Malgré la courbe de réponse moins plate, je pense que ce second cas de figure est bien plus favorable à l'écoute.
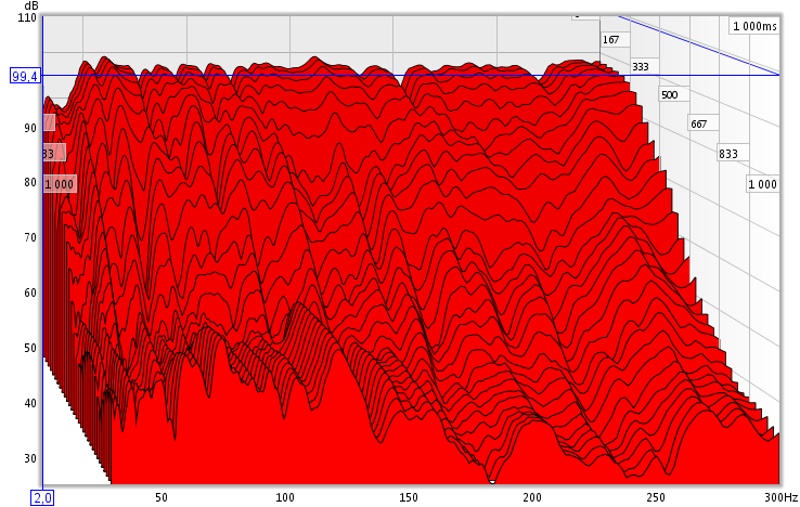
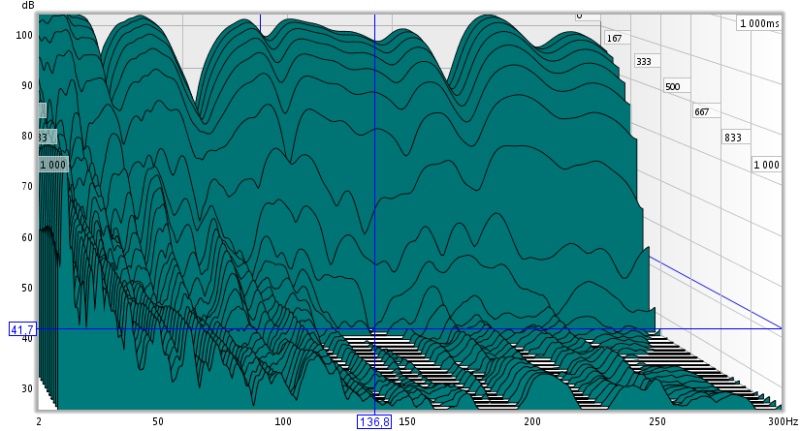
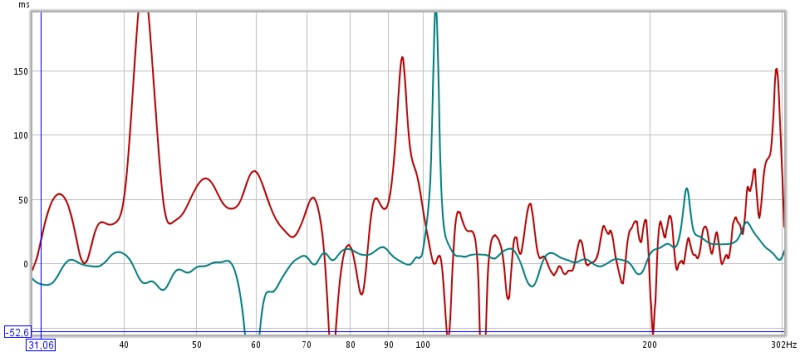
Les courbes de group delay sont également éloquentes:
ce fonctionnement modal très néfaste sur l'écoute et qui est le premier facteur de la signature sonore d'une salle
Ces remarques me gênent et je vais tenter d'expliquer pourquoi.
Ce qui suit est un peu long et compliqué mais vous n'êtes ni obligés de lire ni de comprendre (moi non plus).
Quelques-uns ici connaissent ma réputation d'objectiviste (acharné disent les très mauvaises langues) et grand amateur d'ABX.
O rage, o désespoir, tout est ABXable sauf ce qui a trait à l'acoustique !
Damned, comment peut-on se rendre compte de la plus-value réelle d'un traitement, d'un résonateur, d'une coupelle magique (vous savez bien, c'est la recette miracle confiée par le yéti au copain de Tintin au Tibet)
Depuis quelques années, la puissance des ordinateurs a permis de faire assez facilement de l'auralisation temps réel.
C'est quoi l'auralisation ? C'est une technique qui permet de simuler virtuellement les phénomènes acoustiques et d'écouter directement le son modifié par l'environnement tout en agissant directement sur certains paramètres.
Par plaisir, j'ai donc programmé des logiciels d'auralisation, d'abord pour comprendre certains aspects (réflexions précoces, diffraction,...) et pour écouter et déterminer leur audibilité.
Comme j'ai quand même un petit bagage d'acoustique, je me suis pris au jeu et à partir de la programmation d'une réflexion unique, j'ai finis par une salle virtuelle avec simulation des modes propres, simulation des premières réflexions, déplacement des sources et de l'auditeur, etc...
Evidemment, puisque c'est du temps réel, on est limité par la puissance des processeurs. Je me suis contenté de 2 sources primaires, une soixantaines de sources secondaires,etc...
La grosse limitation est la "sur-acuité" des défauts. Dans la vie réelle, les mouvements de la tête permettent, par exemple, de dissocier certaines réflexions du signal d'origine et d'atténuer l'influence du local.
Quand on utilise un casque en auralisation, on entend sans doute beaucoup plus les défauts. Pour s'approcher de la réalité, il faudrait utiliser un casque avec détecteur de mouvement et correction en temps réel. Je m'y mettrais un jour.
En attendant, on peut déjà écouter et là, je me suis aperçu que les premières réflexions étaient particulièrement audibles mais pas tant les modes propres. Nous voilà revenus au notre sujet de départ.
Donc, j'ai eu l'impression que le traitement du local est en fait plus bénéfique aux réflexions qu'aux modes. Dans un soft, on peut augmenter directement l'absorption pendant l'écoute, alors que pour la vraie acoustique, jamais on ne peut comparer avant/après, avec/sans. Ou alors, il faut se fier à sa mémoire auditive et c'est pas mon genre.
Ou encore, il faut enregistrer des réponses impulsionnelles avant et après traitement, et écouter en passant par un logiciel de convolution, pourquoi pas...
Tout ça était un peu long mais c'est pourquoi je doute de la nocivité réelle des modes propres sauf ceux qui traînent.
Je parle ainsi des modes en général mais je sais pertinement que dans la plupart des pièces non traitées, il y a un ou deux modes bien longs et particulièrement désagréables (ainsi un 106Hz dans mon salon !) et qu'il faut absolument amortir.
Maintenant, si on a chez soi un méchant mode pas très propre comment l'éliminer ? Je ne vais pas aborder ici les façons de corriger mais juste faire un petit calcul d'acoustique.
Beaucoup disent qu'il faut une sacrée épaisseur de matériau amortissant (on dit le 1/4 de la longueur d'onde mais déjà à 125Hz, c'est 70cm !)
Mais après tout, on ne veux pas faire de chambre sourde, on peut se contenter d'amortir ce mode propre juste comme le RT60 de la pièce, non ?
Alors prenons la calculatrice.
La recommandation AESTD1001.1.01-10 qui définit un standard pour l'écoute multicanale demande un TR60 de 0.25s jusqu'à 200Hz puis une tolérance de +0.15s à 125Hz donc 0.4s recommandé à 125Hz.
Supposons qu'un mode perturbateur axial soit présent à cette fréquence. Si on souhaite limiter son trainage au TR max de 0.4s, quel est le coefficient d'absorption nécessaire sur les 2 parois concernées ?
On veut donc qu'au bout du temps 0.4s, l'atténuation soit de 60dB et connaissant la distance entre les murs, on saura combien de fois,l'onde aura été réfléchie et donc atténuée par une paroi.
Par exemple, pendant ce TR de 0.4s, un signal aura voyagé sur 138m. Donc largeur de 4m, il aura passé 34 fois dans l'amortissant des murs . Comme les petits ruisseaux,... déjà un peu d'amortissant devrait bien réduire les modes propres....
Calcul final : alpha=1-10^(-60*L/(344*20*TR)) (où TR représente le RT60 et L la distance entre ces 2 murs). La formule est de moi, vous avez intérêt à vérifier.
Ce qui donne par exemple pour L=4m, avec un TR souhaité de 0.4s à 125Hz, un coef de 0.18 par paroi. Ce 0.18 peut être obtenu par une couche de laine de verre de 50kg/m3 et d'environ 5cm d'épaisseur.
J'ai l'impression que le calcul tient à peu près la route parce qu'en recalculant le TR par la formule de Norris-Eyring, on retombe sur une valeur comparable.
La plupart des acousticiens préconisent des épaisseurs bien plus importantes, pourquoi ?
Modes ? Réflexions précoces ?